On Building Effective Data Science Teams
A comprehensive look on how to build great data science teams from my own experience leading data teams.


As Data Science and AI make their way into every industry under the sun, so do the challenges of building a team capable of building successful AI projects. The demand for that archetypical “Data Scientist” who is the perfect blend of a statistician, programmer and communicator has never been greater. But as the dust settles, we have started hearing stories of failed projects and disenchanted professionals.
As a data science consultant who has worked in various industries, I’ve had the chance to see this trend firsthand. Many people tend to think of Data Science as a new field, and expect it to have growing pains as it becomes mainstream. But we forget where this field came from. This is my attempt to reflect on the qualities that make a successful data team though my own experiences and help business leaders and executives create better AI strategies.
Don’t Forget Your Roots
To begin with, it’s my opinion that we need to think of Data Science as the evolution of existing disciplines rather than being an entirely new one. After all, we’ve been working with data before the computer age began, and the concept of AI has been around since at least the 1950s.
Fields like Knowledge Discovery from Databases, Decision Support Systems, Business Intelligence, Data Mining, Analytics, Predictive Analytics etc. have been around for a long time. The main goal of each of them has been extracting meaningful patterns from data and using that to gain insights and make decisions for the future.
“Data Science” is the latest incarnation of this trend that was enabled by the massive increase in the amount and variety of data available to us in the internet age. It is further fueled by the availability of relatively cheap computational power and new breakthroughs in machine-learning algorithms that can make use of this abundant data. The increased complexity and mathematical sophistication of these new algorithms then created a sudden need for people with advanced degrees who could comprehend them, and thus the AI race began.
But despite the apparent novelty of this technology, it is my firm belief that there is much we can learn from methodologies and best practices followed in those earlier disciplines.
CRISP-DM
The most obvious and often overlooked tool is the CRISP-DM standard. It is an industrial process for structuring your analytics projects that has been around since the 1990s.
The main idea is to divide an analytics project into a number of clearly defined phases. These are — Business understanding, Data understanding, Data preparation, Modeling, Evaluation, and Deployment.
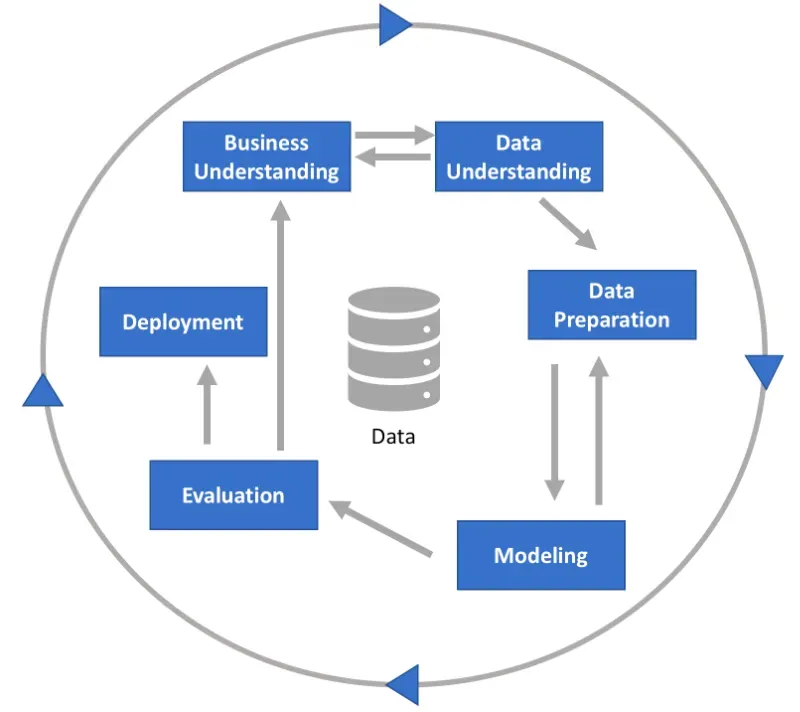
Although this process had some shortcomings and the standard hasn’t been updated recently, the six phases are still useful. In my view, every data professional should read and understand these phases to be truly effective.
The Team Data Science Process (TDSP)
Data Science is a fundamentally iterative process, and the main drawback of CRISP-DM is that it doesn’t incorporate this that well.
TDSP is a modern data science lifecycle process from Microsoft that improves on the older methods. Think of it as what happens when the CRISP-DM gets an agile development makeover, tailored in the age of cloud-based processing.
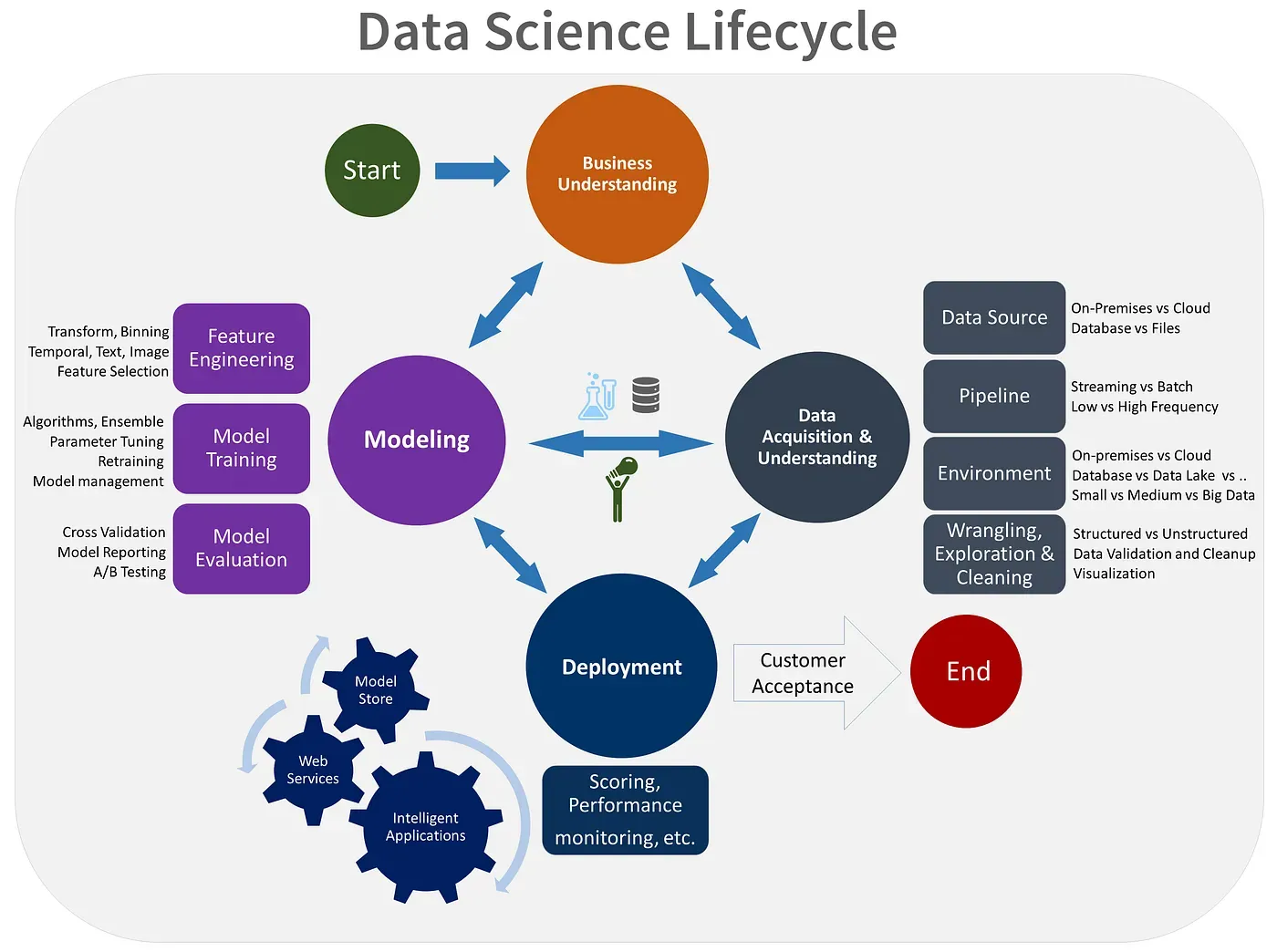
Your company may have its own tailored process based on what you do, but it really helps to know about these foundational processes.
The secret ingredient?
OK, this was a bit of a trick question. I’ve seen companies often get caught up with having the latest and greatest algorithms and computing processors, while taking the data for granted. We may have plenty of data available, but the quality of that data isn’t a given. Good data is still hard to collect, and hence can be the main competitive advantage you could have. The best algorithm cannot guarantee good models unless you feed it good data. As they say — Garbage in, Garbage out.
One of the most overlooked aspects of AI is that most algorithms are available free via open source software or through cloud providers at a very low cost. In a way AI algorithms have become or will be commoditized through these libraries and services.
My advice is to first break your data science roadmap into simple use-cases that everyone agrees on and are achievable in single-digit number of weeks. Also make sure that the data is obtainable, ROI and/or deliverables are clearly defined and the data team is following an iterative execution process.
After you’ve had learned from a few of these cycles, you will be in a much better position to take on more complex and riskier use-cases.
The A-team
Now that we’ve looked at how we can plan our Data Science projects, I want to talk about creating a data team capable of executing that. I’m not going to delve into topics like where to hire or how the hiring process should be, but I’ll talk about the right team composition.
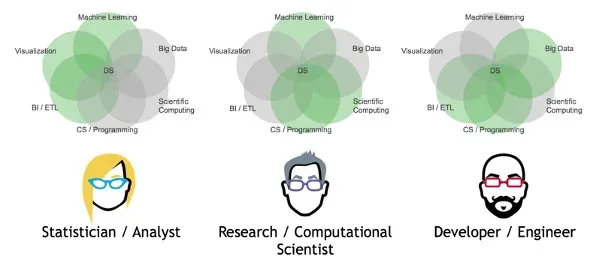
As I said at the beginning of this article, there is much confusion over what a Data Scientist is or does. Given the prestige associated with that job title, anyone whose job has ever been to work with some data seems to have that it in their CVs. I think it’s time to move on from that and have specialized titles based on what people actually do.
Just like we don’t expect a doctor to know every medical procedure or diagnosis, we shouldn’t expect someone to master everything in the AI, either. We must have specialists who know the boundaries of their skill-sets and responsibilities and can work with others to get the job done. Of course, this doesn’t mean there aren’t people who excel at multiple areas or are generalists, just like we have GPs in medicine. Data science is for the most part a team sport.
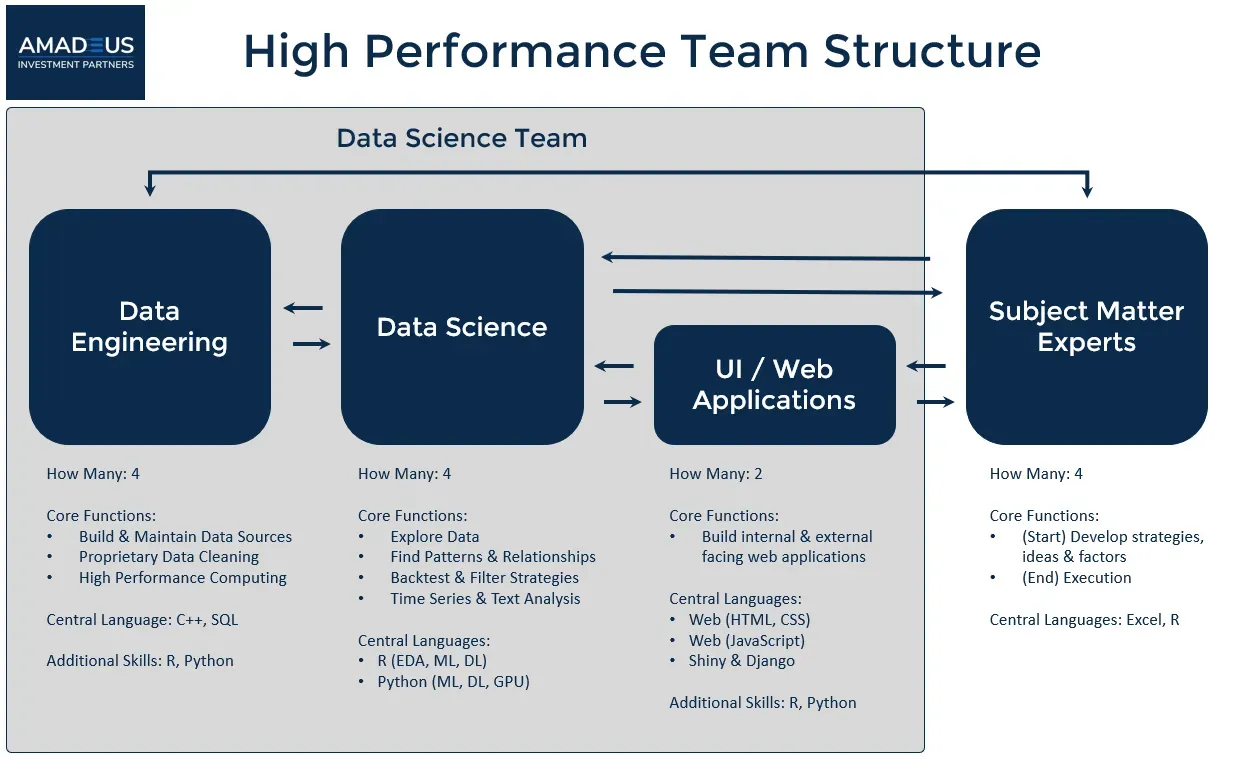
Since, data is the most essential ingredient of any data science strategy the first people you need are Data Engineers. A data engineer is generally someone with good programming and hardware skills, and who can build your data infrastructure. It depends on the size of your data but they are generally comfortable working with big data and cloud technologies, know how to build data pipelines, design databases, and pull data out of them. They will also know how to do look at the data at a basic level, and do simple aggregations for sanity checks on the data quality. But are not necessarily experts in analyzing it.
After you’ve built out your data infrastructure, you will need people who can take that data, clean it, analyze it, run experiments on it and communicate the results. Depending on your business requirements the exact skills vary.
Most of the time this work is done by Data Analysts who are skilled in the processing and cleaning of data, creating statistical inference or predictive models, running experiments, plotting those results, creating reports and providing insights to stakeholders higher up. They’ll mostly be working in Jupyter notebook or RStudio, and have a combination of programming, statistics and machine learning knowledge. We shouldn’t expect them to write production quality code though.
That brings me to the next role. If you are building a data product you will need Machine Learning Engineers in your team. These are not researchers who build machine learning algorithms per se but are data-focused software developers familiar with various data science libraries and know how to write production quality code based on the models developed by the analysts. To do this job they must work closely with Data Engineers, or it might be also done by a math savvy Data Engineer for smaller teams. Most developers looking to enter the data science field should consider this as a good career option.
Sometimes it might also be useful to have a more design-focused Data Visualization Specialist to create highly polished charts and reports to communicate the results of the analysis.
I tend to think of a Data Scientist as someone who is above average in all of the aforementioned roles, and also who knows how to work with the Domain Experts to deliver results. These are collaborators generally outside your team or organization that you bring in to leverage their subject-matter expertise in cases such as medicine, finance, economics, marketing, law etc.
If you are working on problems that require some custom or proprietary data science algorithms, it might then be time to hire someone with a PhD or core research background. They’ll probably have a deep understanding of the theory and algorithms behind an AI field like Conversational AI, Computer Vision, Robotics, Reinforcement Learning, Graphical Models etc. I tend to like the title Research Engineer or Research Scientist for a role like this.
Another important but less talked about role in a data science team is that of a Data Science Manager or Head of Data Science. For smaller teams it might be sufficient to have a senior member of the team who has a good knowledge of all the different roles lead the team. But once the team grows you will probably need someone with a strong technological and business strategy background.
Data Science managers are hands-on leaders who will build the foundation of your data science strategy, recruit and build your team, make sure everybody interacts with each other, have the data and information that they need, and develop the process that the whole team can follow. They are the data team’s interface to the rest of the organization, collaborators and executives. They translate the complex AI jargon to non-experts, and make sure their work is aligned with the strategy of the organization as a whole.
Another important role that managers need to play that is often forgotten is devising a Data Governance and Ethics standard across the team. Most professionals coming in the field are taught the technical skills necessary to do their jobs, but rarely have I seen the importance of data privacy and ethical communication of analysis results being talked about. That results in cases like the Facebook scandal which bring our field in disrepute. Having someone who knows and enforces these values in the team is in my opinion what will make you rise above the rest.
So, these are my views on what makes a successful data science team. In summary the main takeaways are — if we keep our strategy simple to begin with, hire the right people at the right time, leverage the knowledge gathered from previous incarnations of the field, and develop a process that works best for your team and goals, there is no reason why you cannot become an effective data-driven organization.
Note: Currently, I’m putting these principles into practice to build a Data Science team at Leapfrog Technology Inc. Get in touch if you need help building your own team. I’d be happy to share my experiences.



