The Evolution of Search: From Google to Generative AI
An ode to search technology and its role in the coming AI wave.


I’ve always been fascinated by the humble search box and how it shapes our relationship with the digital world. Despite it being a foundational technology of the internet era, it is often not given the attention it deserves. Maybe, it’s because Google dominates the field so much that the term has become a commodity.
Closely following the field, and building my understanding of how this seemingly “magical” technology works, is something that has helped me immensely as an AI practitioner. Now, as chatbots like ChatGPT — supercharged with the latest AI goodness, have captured the world’s imagination, search is once again poised to increase in relevance.
The age of generative AI marks the beginning of the next evolution in search. And, it’s not just me. Even the mighty Google is feeling the challenge to its throne for the first time in its history. So, this is as good a time as any to talk about search technology and its current evolution.
Where Search Comes From
To most of us, the word “search” is synonymous with Google, and it has been our primary gateway to the internet. However, the field of search, or, more broadly, information retrieval, has been around for much longer.
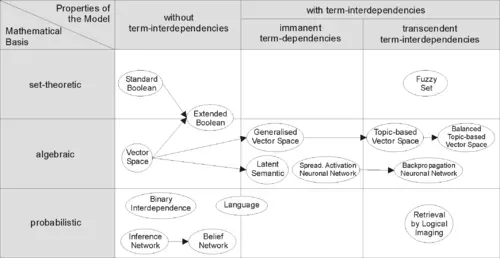
It was developed in the early days of computing as a way to find information as the number of computer systems and data inside in large organizations grew. These early methods were mostly based on the concept of book index. These systems still help us organize knowledge, find the right information quickly, and even discover new information.
If you look closely at the current question-answering (QA) bots like ChatGPT, you will find they essentially provide a search interface for your data. Though, this is not always apparent to everyone.
The main differences these QA interfaces have with traditional search engines is that:
1. Searches are not necessarily performed just on the public web
2. They provide a more interactive and personalized way to interact with our data.
This is a very powerful way to find information and new insights hidden in your data. You can even say that:
LLMs have democratized search for everyone.
How search powers LLMs
Anyone building apps that utilize LLMs will benefit from knowing how search works. Especially if they want to build anything beyond a thin wrapper around these models.
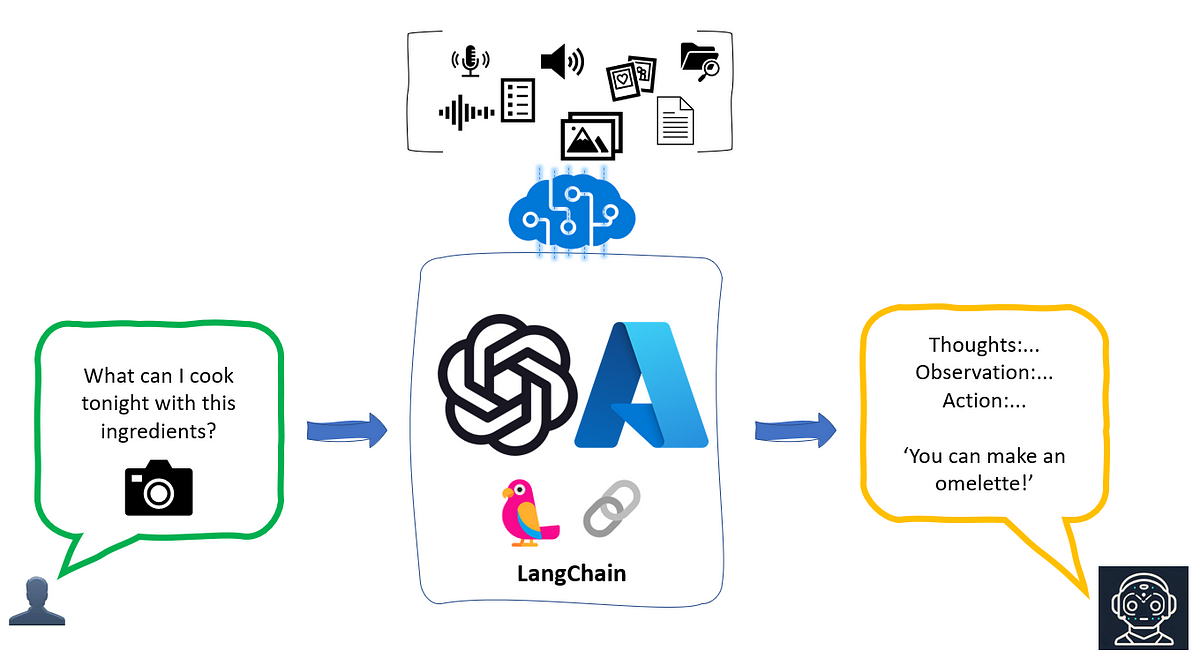
The main ways I’ve seen search technology enabling LLM powered apps are the following.
What do you mean?
One of the hallmarks of the way we use search today is that most of us now interact with it using “natural language” queries instead of just keywords. This can be done either by typing in a text box or by interacting with devices using our voice.
I believe voice will be the dominant way we interact with our devices in the future. But that’s a topic for another blog.
For the system to accurately understand the query and return the most relevant response, detecting the intent of the query is very important. Think how Google knows if you mean the fruit or the company when you type “Apple”.
This is where most new teams will struggle. Especially for queries that are complex and contain more than one entity. There is a whole “art” along with the science to doing this well.
Luckily, a number of effective algorithms have been developed in the field of Information Retrieval using modern Natural Language Processing (NLP) algorithms.
From rags to riches
One important term developers need to get familiar with is Retrieval Augmented Generation (RAG). Currently, it is the most popular method to get a pre-trained LLM model to work on new data that it has not seen before. A major reason for this is that, if used properly, RAG is known to mitigate hallucinations.
At a high level, the RAG algorithm can be described as follows:
- Parse the user query or question and (optionally) extract the main entities it mentions.
- Find the data that is semantically closest to the query in the knowledge base.
- Use the most relevant data points to explicitly provide context for the LLM to respond to that query.
The knowledge base here is usually a “vector database”, though it is not limited to that. A lot of the most promising results have been obtained by combining vector-based retrieval with other technologies like keyword search engines and knowledge graphs to make use of their speed, structure and reasoning ability.
Search Anything
Another feature of using “vector” databases is that instead of storing data as strings or other string-based data structure, they store data as numeric “embeddings”.
The nice thing about vector databases is — almost anything like images, videos, audio etc., can be converted to embeddings. Hence, we are no longer only confined to searching data in string/numeric form. This is called multi-modal search, and is where we are currently heading. So, watch that space.
I hope, I was able to highlight how search is evolving, and will be the driving force behind the current AI revolution. Teams and individuals who want to build successful applications should not overlook this.
Knowing how search and LLMs relate, and how to use search effectively, is the key to unlocking the world of AI.



