Why LLMs Shouldn't Play Doctor, Lawyer, or Scientist
LLMs excel at language, not knowledge.


Multiple studies have shown that humans tend to overtrust AI-generated responses. In the medical domain, for example, this can lead to misdiagnosis, delayed treatment, or inappropriate interventions, with non-experts often failing to detect inaccuracies in AI outputs. This overconfidence isn't just user error—it reflects a false dichotomy we've created as AI builders: either trust the system entirely or reject it outright.
The reality lies in responsible design. By architecting systems that separate language fluency from verified knowledge, we can mitigate the need for blind trust and build AI that earns credibility through transparency and auditability.
What LLMs Really Are: Language, Not Knowledge
LLMs are sophisticated pattern recognition systems trained on vast text corpora. They excel at understanding context, generating coherent prose, and maintaining conversational flow—essentially functioning as the world's most advanced language processors.
Think of an LLM as a brilliant editor at a prestigious publication. This editor can transform a rough draft about quantum computing into compelling, accessible prose. They understand narrative structure and audience engagement. But you wouldn't ask this editor to peer-review the research itself or validate algorithmic efficiency.
Yet this is precisely what we're doing with LLMs in critical applications. The gap between linguistic fluency and domain expertise isn't a flaw in the models—it's a design failure in how we deploy them.
The Hidden Risks
When we treat language models as knowledge authorities, three critical vulnerabilities emerge:
Confident Hallucination: LLMs generate inaccurate information with the same linguistic confidence as accurate data. Unlike human experts who express uncertainty, these models lack metacognitive awareness—they don't know what they don't know. Studies show this can lead to confident nonsense, where outputs sound authoritative but are factually flawed.
Knowledge Decay: Training data becomes stale. Even continuously updated models can't match the dynamic nature of specialized domains where knowledge evolves rapidly.
Source Opacity: LLMs cannot trace their outputs to specific sources or evaluate information credibility. This creates an audit nightmare for organizations needing to validate decision-making processes.
The Apple Paper
A strong case in point for this is Apple's research paper titled, "The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity", which reveals that while large language models (LLMs) may appear to exhibit reasoning capabilities, they are, in many ways, merely simulating thought rather than engaging in genuine human-like reasoning.
The study shows that these models rely heavily on pattern recognition and struggle significantly with complex, unfamiliar tasks, demonstrating an accuracy collapse as problem complexity increases. This suggests that the models' performance is not indicative of true understanding but rather a sophisticated form of statistical mimicry, highlighting the gap between machine-generated outputs and authentic cognitive reasoning.
A Better Architecture: Separation of Concerns
The solution isn't to abandon LLMs—it's to deploy them correctly within a well-architected system that separates language processing from knowledge management.
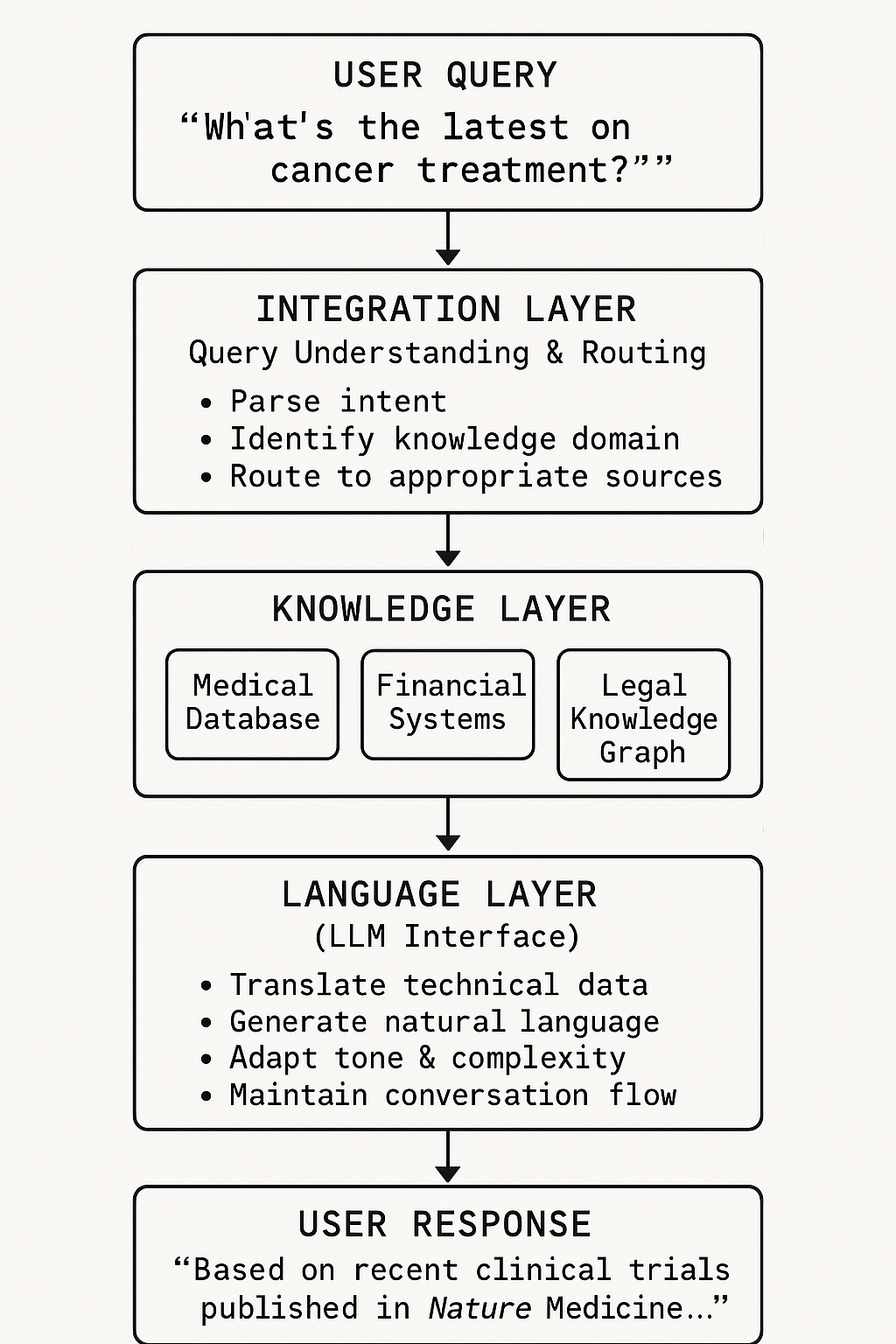
This architecture mirrors successful human organizations. Investment firms don't ask their communications teams to make portfolio decisions, nor do they task analysts with writing marketing copy. Each role has specialized expertise, and value is created through collaboration.
Implementation Strategies
For Developers: Build retrieval-augmented generation (RAG) systems that ground LLM outputs in verified data sources. Tools like vector databases and knowledge graphs enable real-time fact-checking while maintaining auditability.
For Organizations: Audit existing AI implementations to identify where language models are being asked to provide knowledge they cannot reliably possess. Prioritize use cases where LLMs excel—customer communication, content generation, and process automation.
For Users: Approach LLM outputs with appropriate skepticism. Treat them as sophisticated communication tools, not authoritative knowledge sources.
The Path Forward
The future of AI isn't about creating omniscient models—it's about building intelligent systems where each component excels at its designed function. LLMs are extraordinary language processors, and when properly architected within broader knowledge systems, they become powerful tools for human-AI collaboration.
The stakes are too high for architectural shortcuts. In healthcare, finance, legal services, and countless other domains, the difference between a language model and a knowledge system isn't academic—it's the difference between tools that enhance human capability and those that introduce unacceptable risk.
Let's build AI systems that acknowledge these distinctions and leverage the unique strengths of each component. The result will be more capable, more trustworthy, and ultimately more valuable artificial intelligence that serves human needs without overstepping its bounds.



